중복 제거 구문
distinct :행들을 전체조회 후 중복여부 판단 후 제거한다.
SELECT DISTINCT ID,NAME
FROM usertb;
rownum : 조회된 데이터에 번호를 지정하는 역할을 한다.
이 때 정렬값은 rownum에 반영되지 않으므로 서브쿼리를 함께 사용해야한다.
SELECT nn.*,ROWNUM
FROM (SELECT b.* FROM boardtb b ORDER BY BIDX DESC)nn
--역순으로 정렬된 데이터 먼저 만듦
WHERE rownum <= 5;
--위에서 조회된 기준으로 데이터를 자름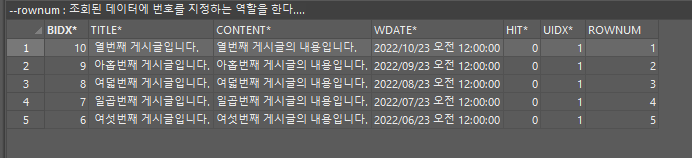
테이블 복제 (백업 테이블을 만들때 많이 사용된다.)
ctas(create table ---- as select)
create table boardtbback as(select * from boardtb);
--이름을 boarddtback으로 변경해서 복제
create table boardtbback2 as(select * from title,content,wdate from boardtb);
--원하는 칼럼만 지정해서 복제가능
group by : 데이터들의 그룹을 지을 때 사용 (집계함수와 같이 사용됨)
select addr,count(*) from usertbl group by addr --한 컬럼만 조회가능
addr로 그룹을 짓고 그룹을 행들의 갯수를 센다.
집계함수(): 조회하고자 하는 칼럼명을 괄호안에 작성
- count() : 행의 갯수를 카운트하는 함수
- avg() : 평균값을 계산하는 함수
- min() : 최소값을 계산하는 함수
- max() : 최대값을 계산하는 함수
- sum() : 칼럼끼리 연산하는 함수
- count(distinct) : 중복데이터는 1으로 센다.
--buytbl에서 운동화를 산 행의 갯수
select count(*) from buytbl where prodname = '운동화';
--usertbl의 출생년도 평균값을 구함.
select avg(birthYear) from usertbl;
--usertbl의 평균키를 구함.
select avg(height) from usertbl;
--usertbl의 최대키를 구함
select max(height) from usertbl;
--usertbl의 최소키를 구함
select min(height) from usertbl;
--usertbl에서 최대키를 가진 데이터의 userid (조건절의 서브쿼리를 사용한다.)
select userid
from usertbl
where height(select max(height) from usertbl);
--usertbl에서 최소키를 가진 데이터의 userid
select userid
from usertbl
where height(select min(height) from usertbl);
--평균 키보다 큰키를 가지는 user의 userid와 username을 조회하세요
select userid, username, height, (select avg(height) from usertbl)as avgh
from usertbl
where height > (select avg(height) from usertbl);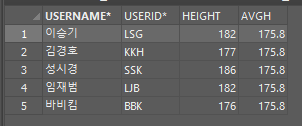
마지막 select문에서 '(select avg(height) from usertbl)as avgh' 는 평균키 값의 칼럼명을 'avgh'로 변경한 것이다.
having : group by의 조건절 (집계함수가 조건이 되는 경우 having 사용)
--총 구매 금액이 200보다 큰 데이터 조회
select userid, sum(price * amount) --가격과 수량을 곱한 값
from buytbl
group by userid
having sum(price * amount) > 200;--가격과 수량을 곱한 값이 200보다 큰 경우--usertbl에서 지역별 평균 출생년도가 1980이상인 지역을 구하시오.
select addr, avg(birthYear)
from usertbl
group by addr
having avg(birthYear) > 1980;
형변환 함수
- cast() : 전체 데이터형 변환
- to_char() : 문자열 형식으로 변환
- to_date() : 날짜 형식으로 변환
- to_number() : 숫자형식으로 변환
to_char() : 데이터를 원하는 문자 포맷으로 변경할 때 사용
select to_char(sysdate,'yyyy-mm-dd HH:mm:ss')from dual;
--첫번째 값 : 변환하고자하는 숫자값 , 두번째 값 : 변환하고자하는 포맷to_date() : 문자열 날짜 포맷을 해당 날짜값으로 변경
select to_date ('2022-11-11','yyyy-mm-dd') from dual;
to_number() : 문자열 숫자를 실제 숫자로 변경
select to_number('00012340') from dual;
cast() : 해당 함수 안에서 변환할 데이터 타입을 명시하는 방법, 모든 데이터타입 사용가능
select cast('2022-11-11', as date) from dual;
--첫번째 값:변환하고자 하는 데이터 , 두번째 값:변환하고자 하는 타입
length() : 문자열의 길이를 구하는 함수
select length('안녕하세요') from dual;
concat() : 문자열을 이어붙이는 함수(두개의 문자열만 합칠 수 있다.)
select userid, concat(mobile1,mobile2) as mobile from usertbl;
여러개의 문자열 이어붙이기
--(010)11111111
SELECT userid, CONCAT(CONCAT(CONCAT('(',mobile1, mobile2),')'),mobile2)AS mobile FROM usertbl;
-- || :여러개의 문자열 이어붙이기
SELECT userid, '('||mobile1||')'|| mobile2 AS mobile FROM usertbl;
문자열 치환
--replace() : 문자열 치환 - 찾은 문자열을 다른 문자열로 바꿔줌
SELECT REPLACE('java hello java','ja','S') FROM dual;
--(기준이 되는 문자열 , 찾고자하는 문자열, 치환하고자하는 문자열) (길이는 무관하다)
--translate() : 문자를 기준으로 치환
SELECT translate('java hello java','ja','S') FROM dual; --자릿수대로 치환'DB' 카테고리의 다른 글
| Select3 (0) | 2022.11.14 |
|---|---|
| Select2 (2) | 2022.11.12 |
| [Oracle]dml . update(데이터 수정) , delete(데이터 삭제) , select(데이터 조회) (0) | 2022.11.09 |
| [Oracle] ddl, dml, dcl 종류 (0) | 2022.11.07 |
| oracle 계정생성 (0) | 2022.11.05 |